日前,由语音社区志愿者组织SpeechColab和清华电子系语音与音频技术实验室,联合语音社区的8个团队,在语音界大神Daniel Povey, Sanjeev Khudanpur, Shinji Watanabe等的大力支持下,通过清华天津电子院AI大数据中心发布了全球最大的多领域英语开源数据集—GigaSpeech。它拥有10000小时的高质量标注音频,比主流的LibriSpeech、TED-LIUM等大一个数量级;且题材丰富多样,远超目前主流的开源数据集。不久前,介绍该数据集的论文已被国际语音顶会InterSpeech2021接收。

关于Gigaspeech:
语音识别的性能,很大程度上取决于训练数据集的规模和覆盖性。现有的语音开源数据集适用领域狭窄,缺少难度挑战,准确率接近饱和。学术界和工业界研究开始分道扬镳,碎片化严重。作为目前全球最大的多领域英语开源数据集,GigaSpeech致力于推动学术界和产业界的共同进步。
GigaSpeech是一个不断发展的、多领域英语语音识别语料库。它拥有10000小时的高质量标注音频,适用于有监督训练任务;以及33000小时的总音频,适用于半监督和无监督训练任务。
数据来源及质量控制
从发音风格和覆盖主题入手,GigaSpeech从有声读物、播客和YouTube上收集了约33000小时的转录音频,以及对应的人工转录文本、人工字幕等,场景上涵盖室内、室外,麦克风近场、远场,朗读、自然语言对话,安静、低噪、高噪,说话人口音、方言、年龄、性别等多样化语音场景;同时在内容上涵盖书籍、时政、气象、名人、体育、科普、心理、经济金融、物理、天文、人工智能、舞蹈、气候变化与可持续发展、企业家传记、商业、历史、棋类竞技、美食、时尚、汽车、房产、电影、数码产品、科幻、儿童、母婴、军事、医疗、慈善、艺术、农业、养殖等众多领域。

在质量控制上,GigaSpeech提供一种新的强制对齐和分段处理pipeline工具,以创建适合ASR训练的句子段,并滤除低质量转录片段。对于有监督训练任务,GigaSpeech提供了5个不同规模的子集。在过滤验证环节,最大训练子集的词错误率控制在4%以下;其它较小规模的子集的词错误率控制在0%。
当前主流的英语学术数据集
当前广泛使用的英语学术数据集如下图所示:其中Fisher约2000小时,题材为电话口语交谈;LibriSpeech约1000小时,题材为朗读式电子书;TED-LIUM约450小时,题材为场馆讲演。

排行榜
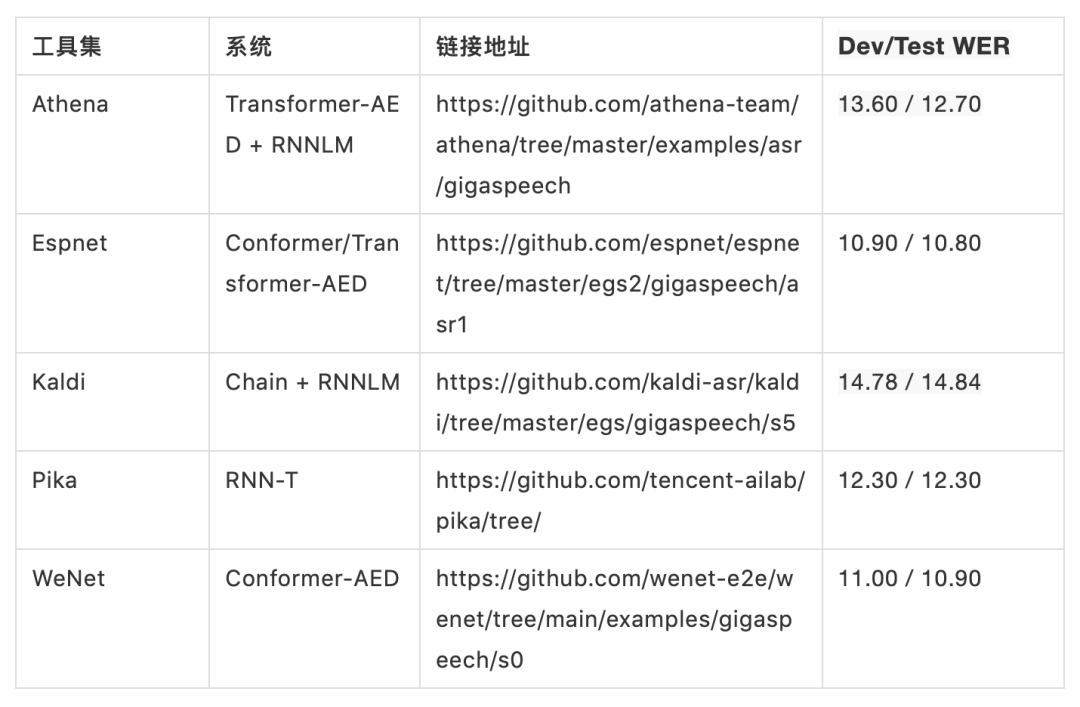
为方便使用,GIgaSpeech为主流的ASR框架提供了baseline的训练脚本,并开放leaderboard排行榜,目前提供的系统包括Athena、Espnet、Kaldi、Pika、WeNet,后续还将继续更新与完善。
关于团队:
SpeechColab和GigaSpeech项目的发起人为陈果果、都家宇和张卫强。

陈果果为清华大学电子系系友,2006年他以优异成绩考入清华电子系。本科四年,他累积了不少在语音处理与识别方面的专业知识,并在语音与音频技术实验室完成了毕业设计。毕业后,他赴约翰霍普金斯大学语言语音处理中心攻读博士学位。博士期间,他曾在谷歌公司实习,开发了基于深度学习的唤醒词识别系统,并被业界广泛应用。同时,博士期间,他还是目前最主流的开源语音识别工具Kaldi的主要开发者之一,以及微软的神经网络工具包CNTK的开发者。博士毕业后,陈果果作为联合创始人创办语音和自然语言处理公司KITT.AI,2017年该公司被百度全资收购后,担任百度主任架构师,并负责百度语音智能设备DuerOS的设备端语音和视觉算法的产品和研发。目前,陈果果担任Seasalt.ai和Vobil.com的联合创始人兼首席技术官。
都家宇硕士毕业于澳大利亚新南威尔士大学电子系,先后任职于清华大学语音技术实验室、百度语音技术部、以及阿里巴巴iDST-达摩院语音组,从事声学模型、解码器、语音唤醒等方面的研发工作。在车载智能语音交互,互联网,在线教育,广电传媒等垂直行业有丰富的项目经验。工作之余参与Kaldi等语音开源项目,发起并推动全球大规模的中文开源语音数据集项目AISHELL-1、AISHELL-2,已服务于近200所国内外知名高校和科研机构。
张卫强为清华大学电子系副研究员,2005年进入清华电子系攻读博士学位,2009年博士毕业留校任教,2017年斯坦福大学访问学者,现为语音与音频技术实验室负责人。他以负责人身份承担自然科学基金重点项目、国家重点研发计划课题等多个重点项目。获教育部科技进步一等奖,获得NIST等多项语音比赛冠军。
在GigaSpeech制作和发布过程中,清华天津电子院的AI大数据平台提供了算力、存储和下载主站点支持。天津电子院于2015年7月成立。在天津滨海新区政府和中新天津生态城管委会的支持下,发挥清华大学高水平科学研究及人才培养的优势,进行电子信息领域科研成果的工程实现及产业化。目前,天津电子院的人工智能大数据平台具有高性能的物理资源配置,可部署各类人工智能算法框架,具有大数据数据集、深度学习训练计算、开发者SDK调用、图像语音识别服务、人工智能行业应用解决方案五大功能板块。
使用申请入口
GigaSpeech数据集已开放,欢迎大家使用。申请入口:
https://forms.gle/UuGQAPyscGRrUMLq6
更多细节,请访问github链接:
https://github.com/SpeechColab/GigaSpeech预印版论文地址(已被InterSpeech 2021接收):https://arxiv.org/abs/2106.06909

