电子系机器学习课题组与第四范式和香港科技大学合作论文《知识图谱学习的双线性评分函数搜索》(Bilinear Scoring Function Search for Knowledge Graph Learning)近期发表于IEEE模式分析和机器智能学报(IEEE Transactions on Pattern Analysis and Machine Intelligence ,IEEE TPAMI)。信息系统研究所姚权铭老师为论文通讯作者,项目负责人。
该论文提出的AutoBLM方法是第一个将AutoML运用到知识图谱学习技术中的工作。通过自动设计给定图谱的评分函数,挖掘语义信息更好的进行图谱建模,大幅降低复杂语义学习的门槛,并在多个任务上达到最优性能。该论文被TPAMI 2022录取,曾力克蚂蚁金服、斯坦福等研究团队,刷新大规模知识图谱榜单OGB记录。
论文链接:https://ieeexplore.ieee.org/document/9729658/
论文和OGB比赛复现代码:https://github.com/AutoML-Research/AutoSF
研究背景
随着AlphaGo在围棋比赛中超越人类冠军水平、AlphaFold在蛋白质三维结构分析上媲美专业设备,机器学习技术已受到整个社会的广泛关注。但是,相关技术缺乏了对真实世界中概念的理解和认识。与此同时,知识图谱则是一种自然包含人类对客观事物理解和认识的图结构化数据,可以有效连接人类对于真实世界的认知与计算机对于物理世界的建模。因此,随着机器学习技术的兴起,知识图谱也常常出现在各种应用中,如利用社交图谱理解人之间的关系、利用城市图谱做人流轨迹分析和利用医药图谱做药物互作用预测。
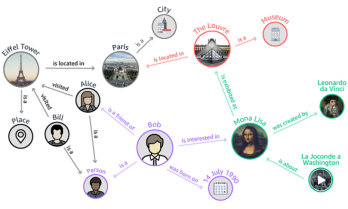
图表1 知识图谱(KG)示例
图1为一个简单的知识图谱示例,我们利用图中的朋友关系,兴趣爱好,属性关系等,预测如(Alice, interested in,?)这样的喜好问题答案。由此,表示学习,即将知识图谱中的信息向量化表示进而与机器学习技术相结合,是前沿研究的重点问题。
但是,由于知识图谱中语义和图的连接关系都非常复杂,传统方法依赖手动设计模型架构很难充分捕捉图谱中有效信息。受自动化机器学习[1,2](AutoML)相关技术启发,我们让“知识自己说话”,利用图谱自身的性质自动设计合适的表示学习模型。
主要内容
知识图谱中基本单元为(头实体、关系、尾实体)这样的三元组,对于不同知识图谱学习任务及数据,其核心研究问题为如何构建评分函数[3](scoring function)来衡量三元组的可编程性。打分函数建模是理解知识图谱中复杂语义信息、挖掘潜在关系的关键。由于不同知识图谱的语义信息差异很大,如社交图谱和医药图谱,AutoBLM采用自动化机器学习技术来自动地设计评分函数。
如图2所示,通常来说知识图谱领域的评分函数是人为定义设计的,这需要很强的专家知识,对任务、数据有着独到的理解。自动化的解决方案,算法根据模型效果的反馈,来自主设计评分函数,通过不断循环迭代来优化评分函数,实现在特定任务数据上低门槛,高性能的评分函数设计。
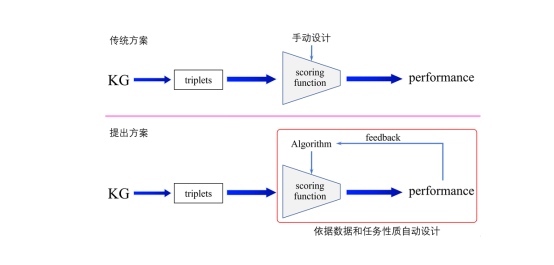
图表2 自动化解决方案示意图
语义驱动的搜索空间
AutoBLM首先对评分函数建立了统一的表达形式及语义驱动的搜索空间。在现有的打分函数中,双线性模型(BiLinear Model, BLM)是一类比较好的模型,其表达能力强、复杂度低、建模效果好。图3展示了两个不同的双线性模型的表达式,以及他们的抽象矩阵表达,DistMult[4]和SimplE[5]不同的矩阵结构,决定了他们能否对各类关系进行建模。常见的关系类型包括对称性(如朋友关系),反对称性(如长辈关系),斜对称性(如属性关系),和逆向关系(如长辈和晚辈)。
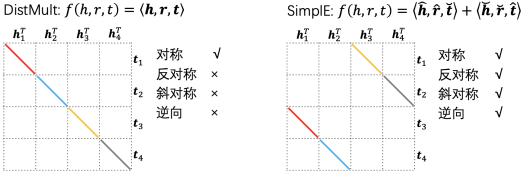
图表3 双线性(BiLinear Model)打分函数示例
为了适应不同知识图谱中的不同语义模式,AutoBLM基于双线性模型,构建了统一的搜索空间,如图4所示,
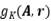 是一个跟关系嵌入
是一个跟关系嵌入 相关的方阵,其表达形式由
相关的方阵,其表达形式由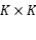 的结构矩阵
的结构矩阵 决定,而评分函数之间的区别就在于结构的不同。这样的搜索空间可以有效覆盖已知的双线性模型,同时有能力探索新颖的、未被尝试的模型。
决定,而评分函数之间的区别就在于结构的不同。这样的搜索空间可以有效覆盖已知的双线性模型,同时有能力探索新颖的、未被尝试的模型。
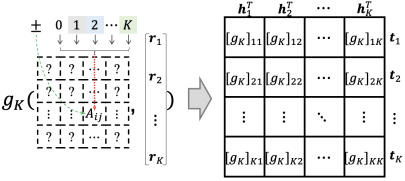
图表4 AutoBLM的矩阵结构搜索空间
裁剪空间的搜索算法
考虑到搜索空间非常巨大且训练和评估每一个结构都需要非常多时间,如何快速有效地搜索更好的结构,是搜索算法所需要关心的问题。AutoBLM在搜索算法的设计上,充分考虑了搜索空间的性质,在给定结构的基础上,对结构先进行一定程度的筛选,再进行模型评估,从而节省开销。如图5所示,AutoBLM利用Filter过滤掉一些非满秩、等价的结构进行初筛,再利用Predictor对结构的对称性特征进行评估,进一步筛选出可能较好地几个结构,对搜索空间进行大幅度的裁剪。在外层,AutoBLM利用渐进式搜索方式,AutoBLM+利用演化的搜索方式,不断迭代、优化,得到更好的结构。
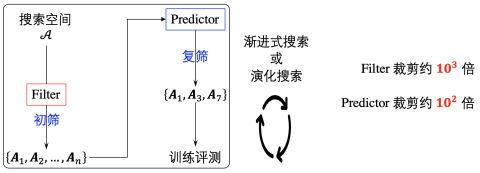
图表5 搜索算法示意图
实验结果
AutoBLM在知识图谱学习代表性任务链接预测上进行了实验,均超过了手工设计模型的效果。此外,AutoBLM还在大型生物知识图谱ogbl-biokg和维基百科图谱ogbl-wikikg2上表现优异,OGB[6]是目前公认的图学习基准数据集代表,由斯坦福大学Jure Leskovec教授团队建立,于2020年国际顶级学术会议NeurIPS上正式开源。以质量高、规模大、场景复杂、难度高著称,素有知识图谱领域“ImageNet”之称,AutoBLM曾在2021年4月分别拿到第一名成绩,刷新榜单记录(见下图AutoSF)。
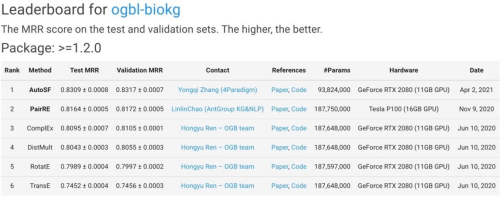
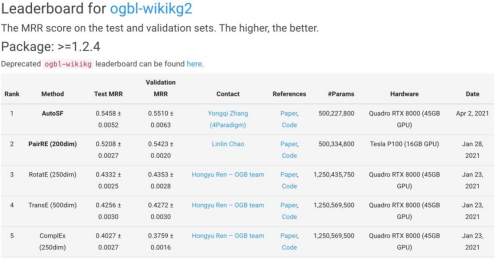
图表6 AutoBLM在OGB上的实验效果
未来工作
AutoBLM(+)的工作重在对知识的理解,对语义的建模。作为一种特殊的图结构,设计合适的图神经网络,捕获知识图谱中结构及复杂语义,同时可以利用自动化的方式,对不同知识图谱任务上语义结构信息的平衡。以上工作解决了知识图谱学习中的建模问题,而调参问题在知识图谱实际应用中同样重要,如何高效地搜索性能良好的超参数是一个研究重点。将AutoBLM(+)拓展到更多元的应用场景,如事件图谱、医药图谱等等,也是潜在研究方向。
欢迎大家关注本组更多工作:https://github.com/orgs/AutoML-Research/
参考文献
[1] F Hutter, L. Kotthoff, and J. Vanschoren. Automated machine learning: methods, systems, challenges. Springer. 2019
[2] Q. Yao and M. Wang, “Taking human out of learning applications: A survey on automated machine learning,” arXiv: 1810.13306, Tech. Rep., 2018.
[3] Z. Wang, J. Zhang, J. Feng, and Z. Chen, “Knowledge graph embedding by translating on hyperplanes,” in AAAI, vol. 14, 2014, pp. 1112–1119.
[4] B. Yang, W. Yih, X. He, J. Gao, and L. Deng, “Embedding entities and relations for learning and inference in knowledge bases,” in ICLR, 2015.
[5] M. Kazemi and D. Poole, “SimplE embedding for link prediction in knowledge graphs,” in NeurIPS, 2018.
[6] Open Graph Benchmark:https://ogb.stanford.edu/

