
近日,清华大学电子系光子计算与集成实验室林星助理教授课题组和上海交通大学电子系熊红凯教授课题组合作,提出了大规模光子神经网络的对偶自适应训练方法,使得网络能够适应大量动态的系统误差累积,实现任务推理性能的巨大提升,在光子神经网络的优化训练领域取得重要进展。
为突破经典冯诺依曼计算机体系架构算力和功耗瓶颈,林星课题组聚焦智能光子计算与芯片研究,以光子作为计算媒介,构建低延迟、高能效、高带宽的光电融合计算处理器,有望在后摩尔时代支撑人工智能大模型的算力需求。
然而,受限于模拟计算系统中所存在的动态系统误差累积,将离线训练得到的光子神经网络模型参数直接部署到处理器时,任务推理性能随着网络规模的增长而急剧下降。现有在线训练方法面临网络梯度无法精确计算、逐层训练效率低、需要增加额外反向传播硬件的难题,难以应用于大规模光子神经网络的训练。
为解决上述难题,课题组提出了用于训练大规模光子神经网络的对偶自适应训练方法(Dual Adaptive Training,DAT),通过网络的精准建模和对偶反向传播,在动态系统误差环境下,成功训练了包含28万神经元的光子神经网络,在分类任务上的训练性能大幅优于当前训练方法。
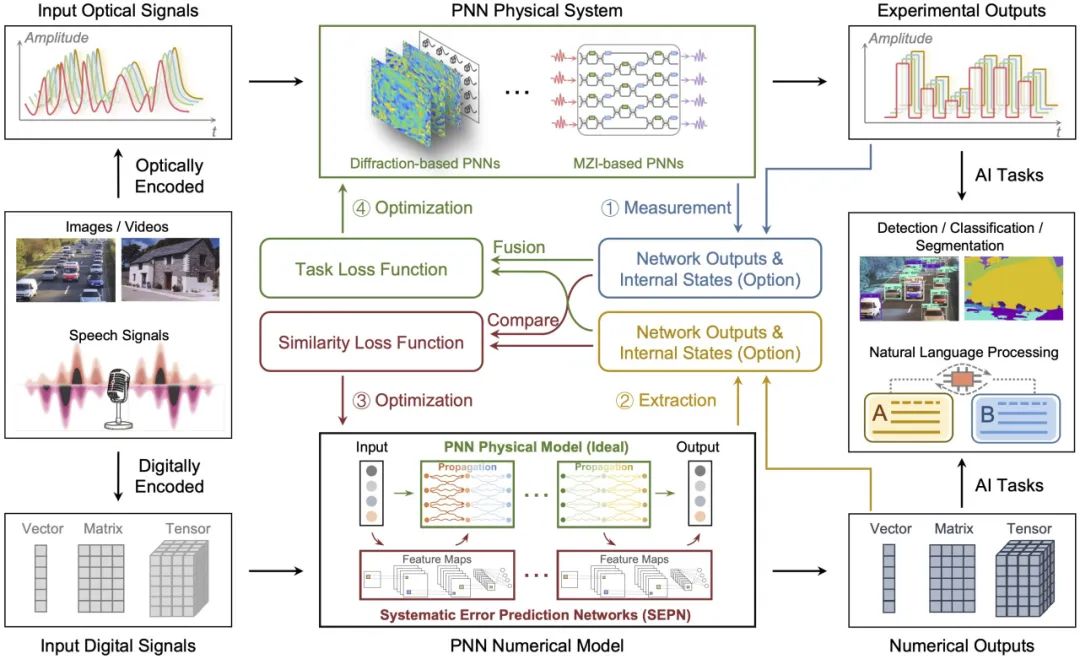
图1.光子神经网络的对偶自适应训练方法
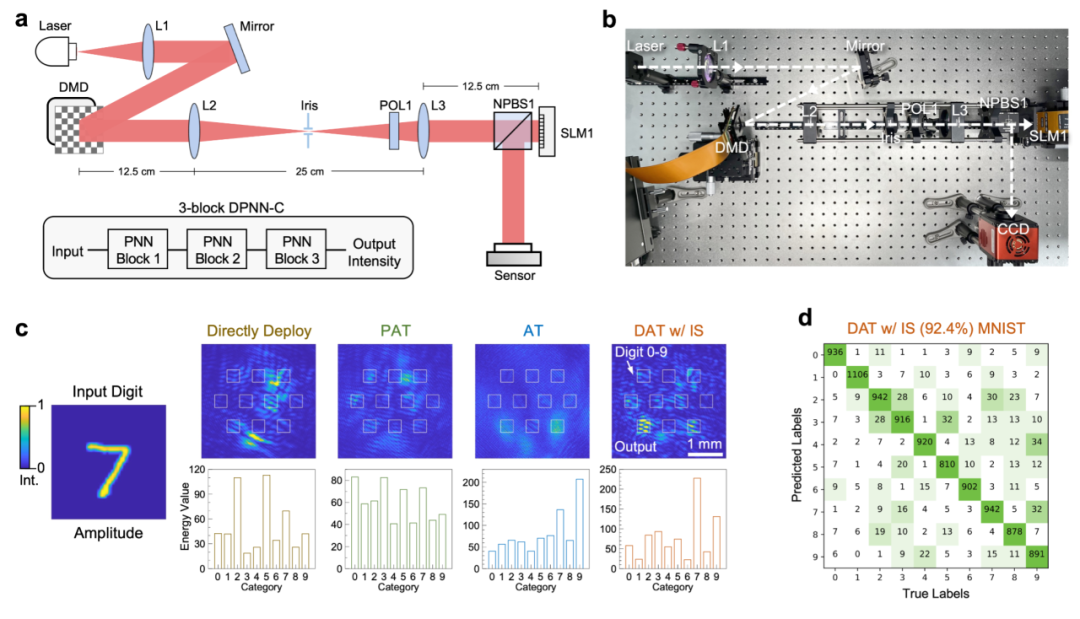
图2.训练空间光子计算系统:衍射光子神经网络
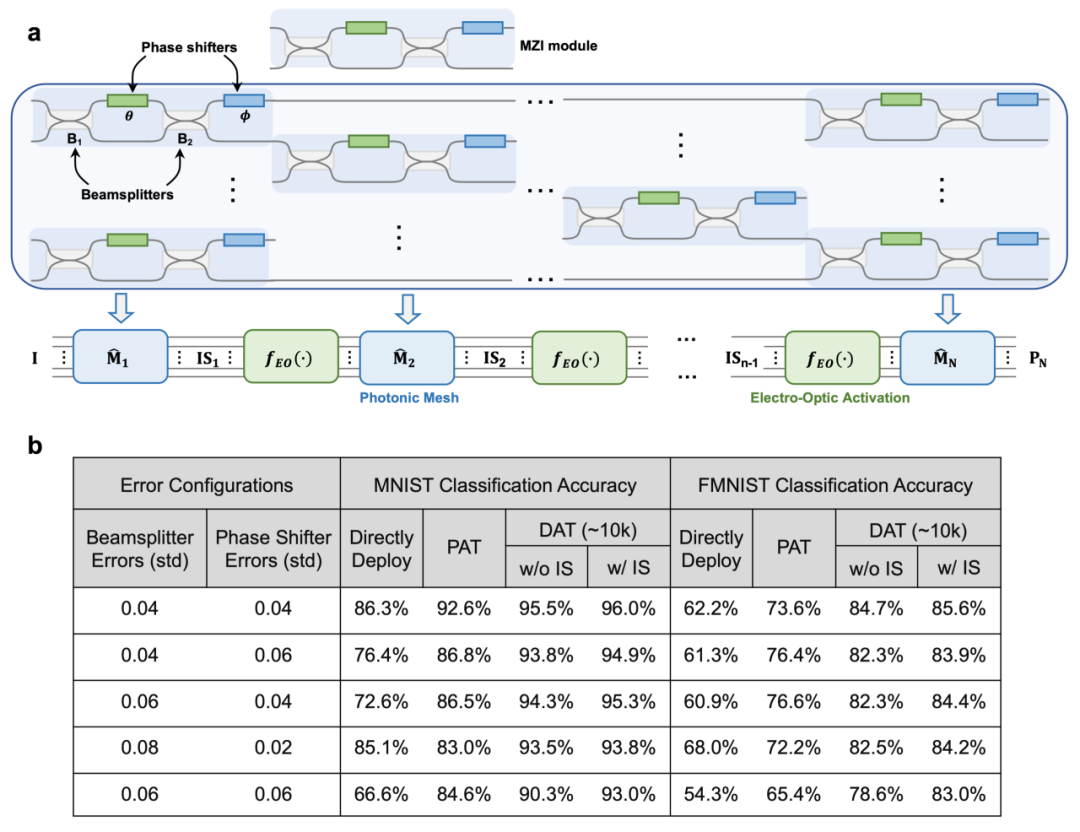
图3.训练片上集成光子计算系统:干涉光子神经网络
课题组在空间光子计算系统的实验平台上,构建了衍射光子神经网络,对比了多种领域前沿训练方法在分类任务上的性能。在严重动态系统误差环境下,所提出对偶自适应训练方法,在MNIST和Fashion-MNIST数据集上训练分类任务,相比参数直接部署方法分类准确率能够分别提升64.1%和66.2%,相比领域前沿方法分类准确率能够分别提升52.8%和67.0%。
课题组进一步在片上集成光子计算系统的仿真平台上构建了干涉光子神经网络,所提出对偶自适应训练方法,同样在MNIST和Fashion-MNIST数据集上训练分类任务,相比参数直接部署方法分类准确率能够分别提升26.4%和28.7%,相比领域前沿方法分类准确率能够分别提升8.4%和17.6%。
研究有效解决了网络梯度精确计算的难题,实现了端到端的网络参数更新,无需增加额外反向传播硬件,可适用于更大规模的光子神经网络训练,并且能拓展到训练任意架构的光子神经网络以及模拟神经网络,为光子神经网络的产业落地和广泛应用提供了有力支撑。
对偶自适应训练方法概览
(视频链接:https://vimeo.com/871480360?share=copy)
近日,该研究成果以“光子神经网络的对偶自适应训练”(Dual Adaptive Training of Photonic Neural Networks)为题发表在《自然·机器智能》(Nature Machine Intelligence)上。
论文通讯作者为清华大学电子系林星助理教授与上海交通大学电子系熊红凯教授,郑紫阳和段正阳博士研究生为论文的共同第一作者,参加研究的作者还包括清华大学电子系博士后陈航、博士研究生高升、工程师张海欧,上海交通大学电子系博士研究生杨睿。
论文链接:
https://www.nature.com/articles/s42256-023-00723-4
来源|清华新闻网
编辑|陶旋姿
审核|汪 玉 李冬梅

